会社などでPHPStanを導入したり荒らしたりする事があるのですが、「まずは入れてみた」状態においては、baselineの記述量をなくしていくぞ!!!!という取り組みがあります。
最終的にはbaselineがなくなるのが健全な筈ですので、その解消作業の進捗やトレンドを分かり易くしておきたいのです。
そんな時に、ふと見つけたのが staabm/phpstan-baseline-analysis でした。
ほーん、気になるhttps://t.co/izhpFQuqj2
— 今日も誰かのにちようび(おいしい鮭親子丼) (@o0h_) 2023年10月22日
コレは、「baselineファイルをソースとして、分析することで、見えてくるものがあるのではないか?」という面白ツールです。
とっても素敵なアイディア!
Software Architecture Metricsを読んだ時に、「GItのデータを用いて、各種活動の発生状況や対象について分析する」といった観点が紹介されていて、なるほど〜と思った*1のですが。
「普段の活動の中で何かしらの動機をもって作成されたり修正されたデータや、あるいは”品質だ!!!管理だ!!!"という意図がなくとも生み落とされる記録」みたいなものであれば、自身の成果物や活動についての状況を示唆するはずだな〜確かに〜〜〜!という。
で、実際にphpstan-baseline-analysisは使えそう・・というか「(ignore)エラー総数だけでも追いたい、俺が欲しい!」と思ったので、セットアップしてみました。
作るものの概要
- 集計した結果、コレまでのトレンドを示すグラフや最新状況について可視化する
- 一目でわかるようにする
- 情報を集約して、1箇所でわかるようにする
- 自動で更新して、新鮮なデータが溜まるようにする
↑をこなすための制約だったり前提条件
- 運用上、baselineファイルは単一のものではなく複数に分割されている
- 複数のbaselineについて個別に & 全体を統合した集計結果の出力に対応させる
- 分析対象ファイルとは別のレポジトリに置きたい
- 自動更新を考える上で、J-SOXが〜〜みたいなことを気にしたくない
- 「対象レポからコードを引っ張ってきて集計にかける」をやる
データは加工していますが、出力イメージはこんな感じになります↓
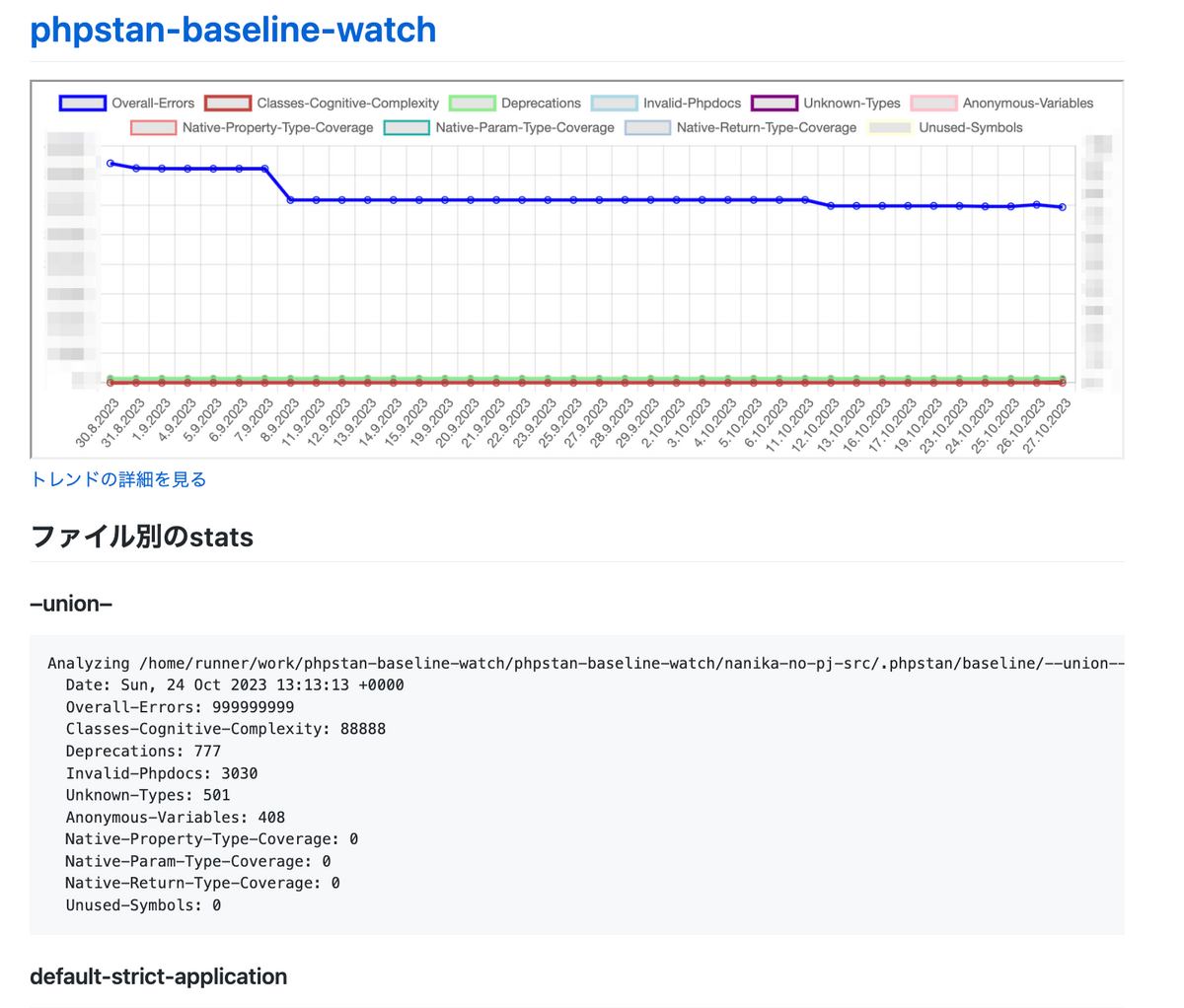
作った
集計を実行するレポジトリを github-org/phpstan-baseline-watch 、集計対象のレポジトリを github-org/nanika-no-pj という名前だとします。
github-org/phpstan-baseline-watch には、
- 集計を実行する処理の実装
- GitHub Actionsで、↑と絡めつつ、
github-org/nanika-no-pjをcloneしてくる && 集計を実行する - GItHub Pagesに可視化結果を出力する
という機能をもたせます。
github-org/nanika-no-pj は、 .phpstan-baselines に(複数の)baselineファイルを持てる構成になっています。
全体像
こんな構成になります。
. ├── .github ├── .gitignore ├── composer.json # phpstan-baseline-analysisを取り入れる ├── composer.lock ├── nanika-no-pj-src # 分析対象レポジトリ ├── docs # gh-pagesの出力対象 ├── main.sh # 集計実行のロジック ├── tmp # 集計時一時ディレクトリ └── vendor
$ cat .gitignore /vendor/ /nanika-no-pj-src/ /tmp/ !/tmp/.gitkeep
集計実行のアクション
実際に集計をキックしたり、その前段階のデータ集めをする実態は、GitHub Actionsのワークフローに委ねることになります。
処理の流れは
- 分析対象のレポジトリを、ignore対象のパスにcloneする
- (github-org/phpstan-baseline-watchの方に)Composer Installを実行する
- 集計実行のロジックをキックする
- 集計結果をcommit&pushする
というものになります。
actions/checkoutは他レポのcloneは可能ですし、fetch-depthを指定することで最新のコミット以外も取得可能です。
今回は「サブディレクトリを掘って、そこにcloneする」という方法を取りましたが、submoduleなんかでも自然だと思います。
ローカルで作業する際に、submoduleではない「自由にいじり放題なディレクトリがあると楽だった〜」くらいのフワッとした理由で、このような形にしています。
集計実行のロジック
workflowファイルに直接書くにはやや煩雑になるので、シェルスクリプトを別出しします。
ざっくりした流れを掻い摘むと、
- 相対日時として、今日〜60日前の範囲で1日毎にイテレーションして
- 初日(=HEAD)の場合だけ、最新スナップショット保持用に集計結果を出力(コミット対象となる)
- スナップショットを取りたい日付(に1番近い)コミットをチェックアウトして
- 個別に分かれているbaselineファイルから、ignoreErrorsを取得してマージするPHPスクリプトの実行し、他のbaselineファイルと並列に配置する
- baselineが設置されているディレクトリの
.phpファイル*2ごとに、集計の実行を行い、一時ディレクトリに結果を出力する - グラフの生成を行い、トップページと詳細ページにmdファイルとして埋め込む
となります。
ちなみに、このスクリプトの要素要素については、殆どChatGPTさんが書いてくれました。ありがてぇ
いくつかポイントを説明していきます
- ポイント①
- ポイント②
- unstagedファイルを
nanika-no-pj-srcの下で一時的に作成しているので、イテレーションの冒頭でお掃除しています
- unstagedファイルを
- ポイント③
- 過去の情報に遡る時 = 「1日」以上前の時だけ、commitを遡ってcheckoutする・・・という分岐なのですが、今思ったらコレ要らないかもですね。
git rev-list -n 1 --before="${day_before} days ago" HEADってHEADにならない?
- 過去の情報に遡る時 = 「1日」以上前の時だけ、commitを遡ってcheckoutする・・・という分岐なのですが、今思ったらコレ要らないかもですね。
- ポイント④
- ポイント⑤
- phpstan-baseline-analysisのRADMEを見ると、いい感じにスナップショット作成対象の日時が反映されている・・・?と喜んだのですが、実際に動かしてみると、集計日時には集計実行時点の現在日時が入るっぽい挙動がありました
- そのため、出力されたファイルから日時のフィールドを直接変更しています。jqが最初から入っているの有り難い
GItHub Pagesの更新
・・・については、ほぼデフォルトのまま(強いて言えばディレクトリを /docs になるように変更したり、スケジュール実行を入れたり)なので、特に言うこともないです。
GitHub上で、PJの settings > pages に行って Build and deployment を GitHub Actions にしてあげれば、雛形を出してくれます。
やった!できたねぇ〜
君も鬼になって、baselineをゴリゴリに削っていこう!